You are here: PSPad forum > English discussion forum > Re: [QUESTION] Batch CP encoding
Re: [QUESTION] Batch CP encoding
#1 [QUESTION] Batch CP encoding
Posted by: pspad | Date: 2017-04-07 05:10 | IP: IP Logged
Current version PSPad 5 works by creating parallel folder with '.OUT' extension, containing files with new encoding.
I have idea if it wouldn't be better to change it. To create parallel folder, e.g. with .BAK extension and store original files before conversion there.
What do you think?
#2 Re: [QUESTION] Batch CP encoding
Posted by: vbr | Date: 2017-04-10 12:14 | IP: IP Logged
pspad:Current version PSPad 5 works by creating parallel folder with '.OUT' extension, containing files with new encoding.
I have idea if it wouldn't be better to change it. To create parallel folder, e.g. with .BAK extension and store original files before conversion there.
What do you think?
Hi,
first, many thanks for adding the batch conversion functionality in PSPad5, it is indeed very useful for some tasks;
and sorry for the following, possibly overcomplicated post - I think, the current funtionality with output in a new location and keeping the original files unchanged) is safer for general usage with the current form of the batch dialog. For changing the files in place and taking a parallel backup, this might require more complex handling, mainly for preventing the loss of the original data by multiple conversion calls in the same path.
I believe, the current dialog for batch encoding could be more informative with regard to conversion settings and process.
E.g. the "input files" and "output files" (or maybe "original..." - "target..."?) areas could be differenciated (possibly with labeled boxes - like in the Find dialog: [Options][Direction][Scope])
The "input" part is probably complete already (mabe [Load file list] would be clearer than just [Load]).
The "output" part of the dialog would contain the target encoding as well as path, which would make the behaviour transparent - there could be options for saving the converted files to the specified path, even for overwritting the files in the original location. Possibly while creating a backup with specified parameters.
The backup behaviour is posibly tricky, as there are multiple options - it could involve the "versioning" - or timestamps e.g. for multiple conversions of the files in the same folders (with unsuitable encoding settings, this could probably corrupt the original data, if the backup folder from the first conversion would be replaced in the subsequent run of the batch conversion).
In the current implementation, the files in the output folder are always rewritten with subsequent calls while always using the original input data, hence the responsibility for overwriting the original files lies on the user (e.g. overwriting in a file manager).
On the other hand, it is probably more intuitive for some usecaes, that the conversion would change the files in-place.
There might be separate "backup" section of the dialog, where a backup-path wil be set (probably defaulting to some parallel folder to the original path (with or without date/timestamp?) - or with warnings before overwritting the backup files with others of the same names).
I'd prefer a more informative button text for the actual conversion
rather than [OK], it could be e.g. [Convert encoding]
a more visible message about completing the batch conversion would be useful too - maybe just within a label of the dialog.
Currently, there is no hint, that the files were processed and the user has to know where to look for the output.
I noticed, that in converting the encoding (individual as well as batch mode) some further "magic" is probably used, than a character conversion - there is possibly some normalisation and decomposition of the accented characters involved - e. g. in a conversion win-1250 to win 1252, č is changed to c, rather than being replaced (?) or ignored as a whole; is it the case?
As a feature requeast, could there be some kind of check, that the target encoding is not supporting some of the original characters? (Or possibly differents modes of conversion on encoding errors (strict conversion with warnings on errors/ replace with a special character/ ignore the unsupported char).
Well, sorry for a possibly overcomplicated suggestion, probably other users can comment on usual usecases
(personally, I try to be rather "defensive" (or paranoid  regarding tools overwritting the original disk content automatically.
regarding tools overwritting the original disk content automatically.
regards,
vbr
#3 Re: [QUESTION] Batch CP encoding
Posted by: pspad | Date: 2017-04-10 13:08 | IP: IP Logged
What i can do quickly is better control description, something like this:
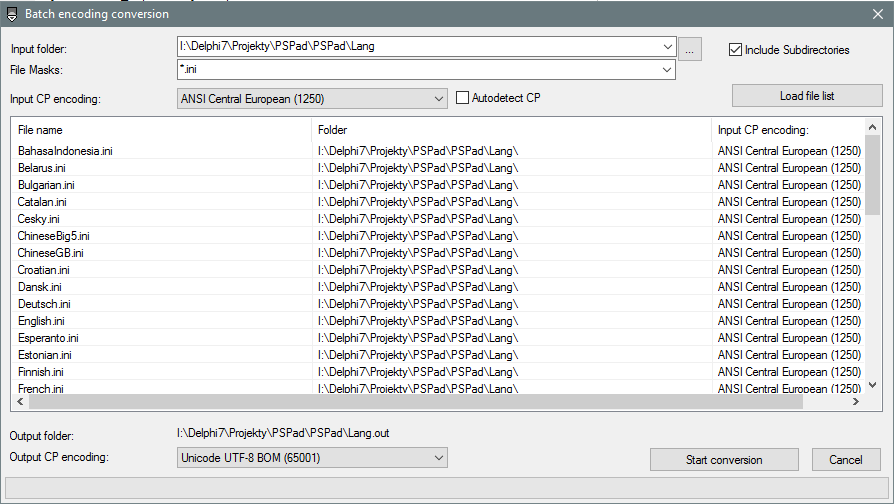
I must study new CP handling possibilities.
It uses some iconv implementation and it's integrated into Delphi. I hope there must be some mechanism to check file before conversion if conversion is possible without char loss.
I am not sure if there will be possibility to remove accent from chars instead of loose it.
Edited 1 time(s). Last edit at 2017-04-10 13:08 by pspad.
#4 Re: [QUESTION] Batch CP encoding
Posted by: vbr | Date: 2017-04-10 14:10 | IP: IP Logged
pspad:What i can do quickly is better control description, something like this:
...
I must study new CP handling possibilities.
It uses some iconv implementation and it's integrated into Delphi. I hope there must be some mechanism to check file before conversion if conversion is possible without char loss.
I am not sure if there will be possibility to remove accent from chars instead of loose it.
Hi,
thanks for the prompt answer, I think, the info about the output path and the improved labels are already very useful.
As for the check about the possible loss by a conversion, I believe the simplest way is to try "roundtripping" , i.e. whether the conversion back to the original encoding results in the original input text, but this can of course be time- or ressource-hungry.
I don't have experience with Delphi, but I would generally expect direct exceptions for unsuccessful encoding (there might be some additional layer handling some cases implicitly).
The removing of accents appears to happen for conversions with limited character set in PSPad5 already - it is actually more user-friendly than completely discarding the accented character, but I'd also prefer some hint, that a conversion is lossy.
It seems, the decomposition of accented characters is used in some form, e.g. in python it can be
>>> unicodedata.normalize("NFD", u"č")
'č'
The letter should (ideally) be displayed in the same way, however, it is a combination of base c and a combining diacritics:
>>> list(unicodedata.normalize("NFD", u"č"))
['c', '̌']
# ̌ (dec.: 780) (hex.: 0x30c) # ̌ COMBINING CARON (Mark, Nonspacing) (Combining Diacritical Marks [768-879] [0x300-0x36f])
In a following encoding conversion, the "base letter" c can be retained, even if č can't be encoded.
vbr
Edited 1 time(s). Last edit at 2017-04-10 14:12 by vbr.
Editor PSPad - freeware editor, © 2001 - 2025 Jan Fiala, Hosted by Webhosting TOJEONO.CZ, design by WebDesign PAY & SOFT, code Petr Dvořák, Privacy policy and GDPR